

Wie GenAI die Pharma- und Life Science-Branche verändert
Dieses Whitepaper verschafft Entscheider:innen in Pharma und Life Science umfassende Einblicke in das Transformationspotenzial, das GenAI über die gesamte pharmazeutische Wertschöpfungskette hinweg bietet. Es legt dar, in welchen Anwendungsbereichen Large Language Models (LLMs) wertschöpfend einsetzbar sind und erörtert die mit dieser Technologie einhergehenden Vorteile und Herausforderungen.
Generative Künstliche Intelligenz (englisch „Generative Artificial Intelligence“ oder kurz „GenAI“) – beziehungsweise Large Language Models (LLMs) als Unterkategorie davon – haben das Potenzial, die gesamte Pharma- und Life Science-Branche fundamental umzugestalten und Biopharma-Unternehmen neue Methoden zur Entwicklung, Produktion und Vermarktung neuer Therapien zu eröffnen. Von Forschung und Entwicklung (bzw. Research & Development, R&D) über die Produktion, kaufmännischen und medizinischen Prozessen bis hin zu administrativen Aufgaben: LLMs sind über die gesamte pharmazeutische Wertschöpfungskette einsetzbar. In diesen Bereichen kann die Technologie potenziell sowohl die Qualität der Arbeitsergebnisse als auch die Produktivität der Mitarbeiter:innen erhöhen und Unternehmenswissen demokratisieren – wodurch die Innovationskraft des Unternehmens steigt.
Allerdings birgt die Implementierung von GenAI in einer stark regulierten Branche auch erhebliche Herausforderungen. Die erfolgreiche Bereitstellung und Nutzung solcher Lösungen erfordert nicht nur strategisch durchdachte und skalierbare Anwendungen, sondern auch ein effektives Managen aller damit verbundenen Prozesse. Um diese Anforderungen zu erfüllen, müssen Technologie und Geschäftsstrategie an einem Strang ziehen und sicherstellen, dass eine GenAI-Lösung genau auf die einzigartigen Bedürfnisse der eigenen Organisation zugeschnitten ist.
In einem sich rasant weiterentwickelnden Umfeld ist es für Unternehmen von größter Bedeutung, proaktiv auf die Anwendung von LLMs hinzuarbeiten. Andernfalls laufen sie Gefahr, Marktanteile an Mitbewerber zu verlieren.
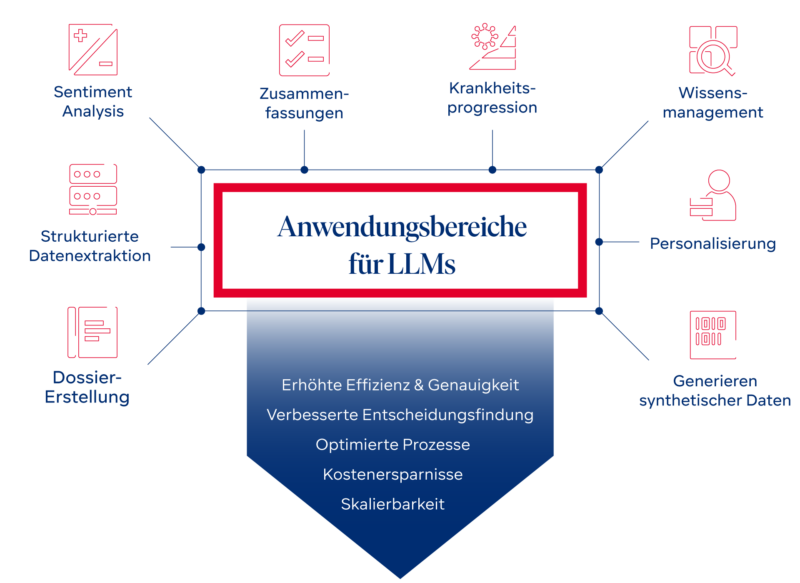
Im Folgenden schauen wir uns drei wichtige Anwendungsbereiche für LLMs näher an:
Sie profitieren anhand dieser Beispiele von unseren praktischen Erfahrungen in der Entwicklung und Umsetzung von GenAI-Lösungen und könne die Einführung von GenAI in Ihrem Unternehmen beschleunigen.
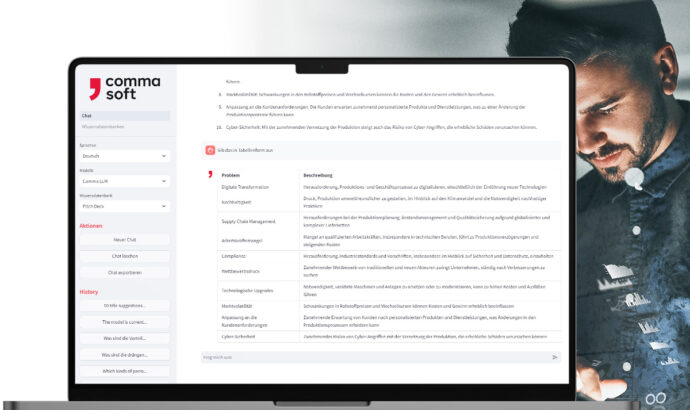
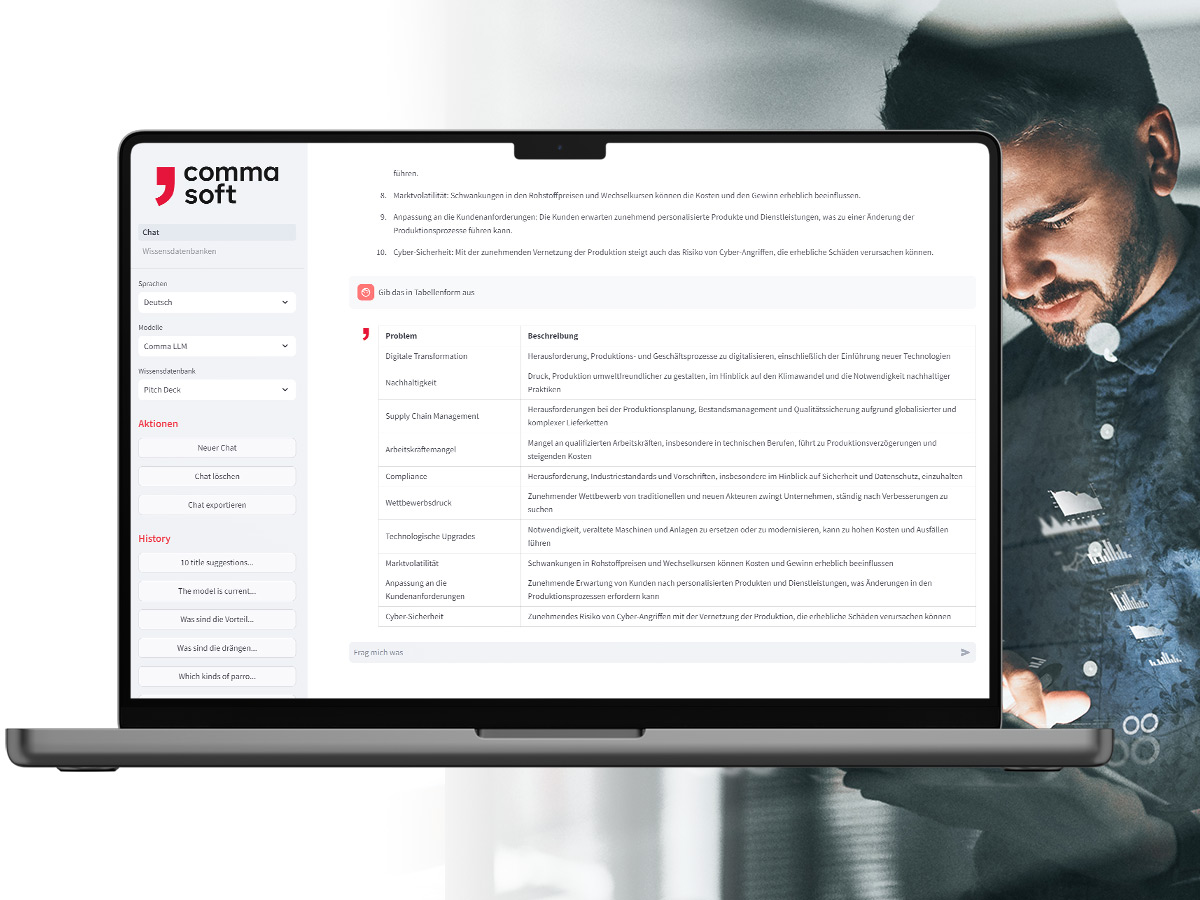
Alan: Die sichere GenAI-Lösung
Mit Alan, dem Comma LLM, nutzen Sie Ihren unternehmenseigenen GenAI-Service – ready to use in einer europäischen oder deutschen Cloud oder on-premises. Hier binden Sie Ihre eigenen Informationen ein und kontrollieren Sie selbst, was mit Ihren Daten passiert und wie Ergebnisse generiert werden.
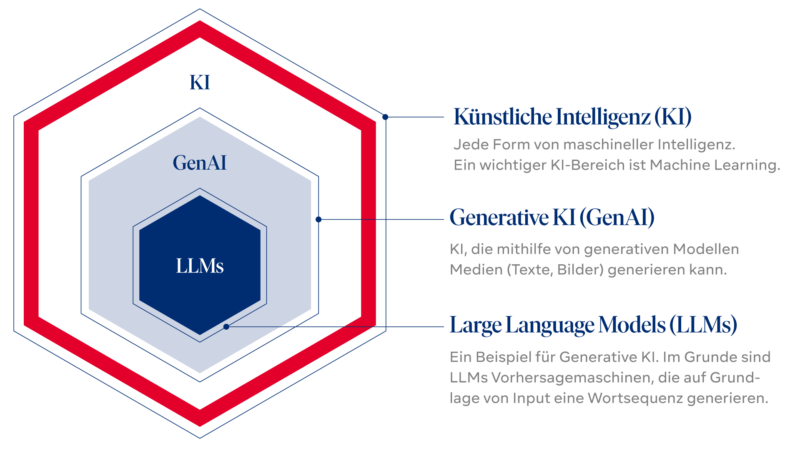
Exkurs zu den Begrifflichkeiten
Large Language Model – LLM – Generative KI – Prompting: Die Begrifflichkeiten können etwas verwirrend wirken. Wer tiefer in das Thema eintauchen möchte, findet hier weitere Details.
-
Jede Form von maschineller Intelligenz wird als KI bezeichnet. Im allgemeinen Sprachgebrauch wird der Begriff „Künstliche Intelligenz“ verwendet, wenn eine Maschine „kognitive“ Leistungen wie Lernen und Problemlösen nachahmt, die sonst mit menschlicher Denkleistung assoziiert werden. KI ist ein Forschungsbereich der Informatik, in dem intelligente Maschinen entwickelt und studiert werden. Ein wichtiger Bereich der modernen Forschung zur Künstlichen Intelligenz ist maschinelles Lernen (Machine Learning): Dabei lernt die Maschine mithilfe von riesigen Datenmengen, Bilder zu klassifizieren oder Zeitreihen vorherzusagen.

Wissen mit LLMs managen
Die Pharmaindustrie ist sehr datenintensiv. Aus diesem Grund ist das Wissensmanagement für diese Branche immens wichtig – besonders in Bezug auf Standard Operating Procedures (SOPs), die mit unzähligen Dokumenten verbunden sind, an denen mehrere Stakeholder mitwirken. Sie müssen häufig umfangreiche Dokumente zu Verfahren, technische Berichte und Forschungserkenntnisse manuell durchsehen. Für jede Funktion, jede Forschungs-, Produktions- und Testphase sind eigene Protokolle zu verfassen und Verfahren genau zu befolgen.
Standard Operating Procedures: Effizienz & Skalierbarkeit statt langer Suche
Aktuell ist das Wissensmanagement in der Pharmaindustrie größtenteils papierintensiv und mit vielen manuellen Arbeitsschritten verbunden. SOPs werden in Archiven aufbewahrt, und jede:r Beteiligte muss sich die jeweils relevanten Informationen selbst aus einem Papierberg heraussuchen. Dazu kommt, dass diese Dokumente häufig sehr fachsprachlich geschrieben sind. Das erzeugt eine zusätzliche Hürde für fachfremde Stakeholder wie zum Beispiel abteilungsfremde Kollegen – und führt zu Kommunikationslücken.
Wie können die Herausforderungen des Wissensmanagements in der Pharmabranche überwunden werden?
Das aktuell praktizierte Wissensmanagement stellt seine Nutzer:innen vor einige Herausforderungen. Am offensichtlichsten ist seine Ineffizienz – das Durchsuchen Hunderter Dokumente kostet Zeit und kann sehr mühsam sein. Komplexe Ausdrucksweisen oder spezifische Fachsprache können zur Fehlinterpretation von Informationen und somit zu Fehlern in Abläufen führen. Dadurch kann die allgemeine Produktivität der Organisation sinken und es kann zu rechtlichen Konsequenzen kommen.
Das System lässt sich außerdem nicht skalieren. Wenn eine Organisation wächst, steigt die Anzahl an SOPs und anderen Dokumenten sprunghaft an. Es kostet dadurch mehr Zeit und Ressourcen, das angesammelte Wissen zu verwalten und darauf zuzugreifen. Diese Situation führt aktuell häufig zu Engpässen, die den Entscheidungsprozess verlangsamen. Diese Verzögerung kann Konkurrenten im Rennen um Innovationen und Patente einen Vorteil verschaffen.
Welche Chancen eröffnet die Verwendung von LLMs für das Wissensmanagement?
LLMs können die Handhabung von Wissensmanagement und SOPs in der Pharmaindustrie revolutionieren. Da diese Modelle in der Lage sind, Texte fast wie ein Mensch zu lesen, zu verstehen und zu generieren, sind sie perfekt für die Verwaltung großer Informationsmengen geeignet. Sie können so trainiert werden, dass sie SOPs lesen, relevante Informationen extrahieren und sie auf die entsprechenden Anfragen hin aufbereitet ausgeben. Das Ziel der Pharmaunternehmen könnte eine demokratisierte KI-Umgebung sein, in der alle Mitarbeiter:innen unabhängig von ihren Positionen oder technischen Vorkenntnissen auf SOPs zugreifen und diese verstehen können. Das LLM wäre in diesem Szenario ein intelligenter Assistent, der allen Stakeholdern hilft, effektiv zu kommunizieren und somit die Effizienz der gesamten Organisation steigert. Statt manuell diverse Dokumente durchsuchen zu müssen, können die Mitarbeiter:innen dem LLM einfach per Prompt eine Frage stellen. Das LLM kann die Anfrage verarbeiten, die SOP-Datenbank durchsuchen und die Antwort direkt ausgeben – unter Zuhilfenahme von RAG auch mit Belegen der relevanten SOP-Passagen.
Vorteile beim Wissensmanagement mit LLMs
- Skalierbarkeit: Ein LLM kann Tausende Mitarbeiter:innen gleichzeitig mit Informationen versorgen und Fragen in Verbindung mit verschiedenen Funktionen, Phasen und Verfahren beantworten.
- Kommunikationslücken schließen: Da ein LLM Texte in der Sprache der jeweiligen Benutzer:innen auswerten und generieren kann, ist es sehr gut dazu geeignet, Kommunikationslücken zu schließen. Es kann auch Fachsprache übersetzen und auf einfache Weise erklären, sodass auch die Verständigung über unterschiedliche Teams hinweg vereinfacht wird.
- Kostenersparnisse: Die Demokratisierung von KI ermöglicht es allen Mitarbeiter:innen, LLMs zu verwenden und deren Vorteile zu nutzen. Durch den deutlich reduzierten Zeitaufwand für die Suche nach und das Verstehen von SOPs können Kosten eingespart werden.
- Geringeres Fehlerpotenzial: Da die zur Verfügung gestellten Informationen genauer sind, lässt sich auch die Fehlerquote senken.
Herausforderungen bei der Verwendung von LLMs für das Wissensmanagement
- Sicherheit: Unternehmen, die ein LLM verwenden, müssen sicherstellen, dass keine internen Informationen nach außen dringen. Da viele GPT-Tools als Cloud-Services auf US-amerikanischen Servern laufen oder ihre Datenschutzvorkehrungen nicht vollständig überprüfbar sind, eignen sie sich nicht für den Einsatz in diesem Kontext. Besonders Unternehmen in stark regulierten Branchen sollten darauf achten, dass das LLM der Wahl ihren Ansprüchen an ein sicheres, den Regularien entsprechendes und kontrollierbares LLM genügt.
- Updates: Wenn eine eigene GenAI-Lösung implementiert werden soll, müssen die Unternehmen sicherstellen, dass das LLM regelmäßig mit den aktuellen Daten (beispielsweise neuen Vorschriften) trainiert wird bzw. dass es diese Daten über RAG abrufen kann.
- Sprache: Gängige GenAI-Tools sind nur nützlich, wenn ihre Benutzer:innen in der Lage sind, effektive Prompts zu verfassen. Um sicherzustellen, dass dies der Fall ist und das LLM in vollem Umfang genutzt werden kann, sollte die Nutzung so einfach wie möglich sein – Prompts sollten daher in der Muttersprache des jeweiligen Users möglich sein.
- Business-Kontext: Das Training für marktübliche GenAI-Lösungen enthält keine Fachbegriffe für die Pharmaindustrie. Daher sollten Unternehmen überprüfen, ob das LLM der Wahl für ihre spezifische Terminologie trainiert wurde bzw. ob es möglich ist, das LLM mit geringem Aufwand entsprechend zu trainieren.
Weitere Use Cases für das Wissensmanagement mit LLMs
Research and Development (R&D):
Forschende können LLMs nutzen, um schnell auf SOPs, wissenschaftliche Publikationen und Studien zu den diversen Phasen der Arzneimittelentwicklung zuzugreifen und so den R&D-Prozess beschleunigen.
Qualitätssicherung (Quality Assurance, QA):
QA-Teams können mit LLMs die Compliance und regulatorischen Standards überprüfen und so das Non-Compliance-Risiko senken.
Produktion:
Produktionsteams können LLMs verwenden, um SOPs, Spezifikationen und Dokumentationen für diverse Prozesse richtig zu verstehen, sodass Produktionsfehler auf ein Minimum beschränkt werden.
Training und Onboarding:
Neue Angestellte können sich über LLMs schnell mit Compliance-Anforderungen und dem spezifischen Wissen ihrer Abteilung vertraut machen, sodass Training und Onboarding weniger Zeit und Aufwand kosten.
Compliance-Management:
Compliance-Teams können mithilfe von LLMs sicherstellen, dass die Unternehmenspraktiken den aktuellen nationalen und internationalen Bestimmungen entsprechen, indem sie spezifische Standards abfragen.

Das bringt Wissensmanagement mit LLMs
Die Nutzung von LLMs zur Verwaltung von SOPs und vielen weiteren wichtigen Prozessen kann potenziell einen Paradigmenwechsel im Wissensmanagement der Pharmaindustrie herbeiführen. Indem sie Wissen leicht zugänglich und verständlich machen, können LLMs die Effizienz steigern, die Kommunikation verbessern und zu deutlichen Kostenersparnissen führen.
Mit der Demokratisierung von KI mithilfe von LLMs beginnt ein neues Zeitalter, in dem alle Mitarbeiter:innen unabhängig von ihrer Funktion oder ihren technischen Vorkenntnissen von KI profitieren können. Letztendlich wird die Pharmaindustrie dadurch effizienter und produktiver agieren.

Daten mit LLMs strukturiert extrahieren
Die Pharmaindustrie verwaltet viele Daten und Informationen aus diversen Quellen: Protokolle, klinische Studien, elektronische Gesundheitsakten und vieles mehr. Die Daten sind vielfältig und komplex. Sie enthalten viel impliziertes Wissen und viele fachspezifische Abkürzungen. Außerdem ist ein Großteil dieser Daten unstrukturiert und wird folglich zu wenig zur Entscheidungsfindung und für die Forschung herangezogen.
Von Datenwildwuchs zu Data Maturity
In Pharmaunternehmen fallen immer mehr Daten an. Häufig werden diese in historisch gewachsenen und größtenteils isolierten Anwendungen gespeichert. Die Notwendigkeit, diesen Wildwuchs effizient zu verwalten und Data
Maturity zu erreichen, wird immer dringender. Mithilfe von LLMs können Unternehmen all ihre Daten ordnen, indem sie strukturierte Informationen aus unstrukturierten Quellen extrahieren. Dank der LLM-basierten Datenextraktion wird es möglich, wertvolle Informationen zugänglicher zu machen und über mehrere Prozesse und Abteilungen hinweg bessere Entscheidungen zu treffen – auf eine viel effizientere und schnellere Weise als je zuvor.
Wie können die Herausforderungen bei der Datenextraktion überwunden werden?
Eine der größten Herausforderungen ist die Extraktion relevanter Informationen aus der riesigen Menge an verfügbaren strukturierten und unstrukturierten Daten. Die manuelle Datenextraktion kostet Zeit, ist sehr aufwändig und Fehleranfällig. Zudem sind die Informationen häufig auf viele verschiedene Arten aufgezeichnet worden oder es wurden unterschiedliche Begriffe verwendet, was die Suche nach relevanten Informationen zusätzlich erschwert.
Schließlich sind in vielen Fällen große Datenmengen isoliert in verschiedenen Systemen und unterschiedlichen Versionen gespeichert. Es besteht das Risiko, dass bei der Datenextraktion veraltete Daten verwendet werden, und es ist nicht leicht, herauszufinden, welche der vorhandenen Versionen die aktuelle ist oder ob alle relevanten Informationen in den aktuellen Versionen aktualisiert wurden.
Welche Chancen eröffnet die Verwendung von LLMs zur Datenextraktion?
LLMs sind eine vielversprechende Lösungsmöglichkeit für diese Herausforderungen. Sie können den Kontext und die Semantik eines Texts analysieren und sind daher sehr gut zur Datenextraktion geeignet. Sie können den Datenextraktionsprozess automatisieren, Fehler reduzieren, veraltete Datenversionen identifizieren und Erkenntnisse aus den aktuellen Daten sichtbar machen. Die Daten lassen sich so leichter organisieren und analysieren, sodass für die Organisation wichtige Muster und Zusammenhänge besser identifiziert werden können. LLMs können domänenspezifische Abkürzungen und impliziertes Wissen in verschiedenen Dokumenten identifizieren und analysieren. So erhöhen sie die Genauigkeit und Verlässlichkeit der Daten.
Vorteile bei der Datenextraktion mit LLMs
- Effizienz: LLMs können verschiedene Datentypen aus unterschiedlichen Quellen innerhalb von Sekunden extrahieren und analysieren. Es ist nicht mehr notwendig, manuell Daten herauszusuchen und zu extrahieren. Außerdem erhöht die Extrahierung mit einem LLM die Geschwindigkeit und Genauigkeit der Datenextraktion.
- Skalierbarkeit: LLMs können problemlos große Datenmengen verarbeiten. Die Extraktion aus der stetig steigenden Datenmenge lässt sich mit LLMs einfach an den Bedarf anpassen.
- Daten FAIR machen: FAIR steht für „Findable, Accessible, Interoperable und Reusable“. Diese Eigenschaften sind ein wichtiger Schritt hin zu einem datengetriebenen Unternehmen. LLMs können relevante Metadaten aus strukturierten und unstrukturierten Quellen extrahieren und so helfen, die erste Hürde zu überwinden und die Daten mithilfe von Metadaten besser durchsuchbar zu machen. Auch zu den anderen FAIR-Dimensionen können LLMs einen bedeutenden Beitrag leisten.
- Standardisierung: LLMs können die Informationen und Daten in Dokumenten harmonisieren und so Inkonsistenzen und Subjektivität reduzieren. Das unterstützt die Kommunikation und das Verständnis von Daten innerhalb des gesamten Unternehmens und ermöglicht eine Standardisierung der Sprache.
Herausforderungen bei der Verwendung von LLMs für das Wissensmanagement
- Kostentransparenz: Viele GenAI-Tools bieten Abonnements an, bei denen nach der Anzahl an Tokens bezahlt wird. Das kann die Kosten erhöhen. Unternehmen, die ein LLM verwenden möchten, sollten auf die Art der Lizenzierung achten und ein LLM auswählen, das zum verfügbaren Budget passt. Beispielsweise kann ein Preismodel ohne Beschränkung der Benutzeranzahl sinnvoll sein.
- APIs: Wenn ein LLM zur Datenextraktion verwendet wird, muss das Unternehmen das LLM mit allen relevanten Anwendungen verbinden, in denen die Daten gespeichert sind. Nicht alle GenAI-Tools unterstützen alle APIs. Es ist wichtig, sicherzustellen, dass die volle Integration möglich ist.
- Zugang: Um Daten aus den verschiedenen Quellen zu extrahieren, müssen die LLMs Zugang zu den entsprechenden Quellen haben. Dazu ist es nicht nur wichtig, dass es technisch möglich ist, auf alle Daten zuzugreifen. Auch die entsprechende Governance und/oder das Rechte- und Rollenkonzept muss vorhanden sein um sicherzustellen, dass die Benutzer:innen nur Zugang zu extrahierten Informationen haben, die sie einsehen dürfen.
Weitere Use Cases für die Datenextraktion mit LLMs
Patientendaten:
Mit LLMs können Patienteninformationen aus elektronischen Gesundheitsakten extrahiert und kategorisiert werden. Auch fehlende Patientendaten lassen sich aus unstrukturierten Texten (z. B. aus Entlassungsberichten) wiederherstellen.
Wettbewerbsrelevante Informationen:
Durch die Analyse von Zeitungsartikeln, Blogbeiträgen und anderen relevanten Inhalten können LLMs Muster und Trends (z. B. Veränderungen in der Wettbewerbslandschaft, Preisänderungen, veränderte Patientenpräferenzen) erkennbar machen, die für die Branche oder den Zielmarkt eines Unternehmens von Bedeutung sind. Diese Informationen können für strategische Entscheidungen genutzt werden und helfen, neue Geschäftsmöglichkeiten frühzeitig zu erkennen und zu nutzen.
Regulatorik:
Mit LLMs können bestimmte Vorschriften für einen bestimmten Zweck aus Tausenden Seiten mit regulatorischen Informationen extrahiert werden. Dies ermöglicht und beschleunigt die das Einhalten von Compliance und Regulatorik.
Post-Market-Überwachung und Pharmakovigilanz:
Sowohl Erkennung, Bewertung, Verständnis und Prävention von Nebenwirkungen oder anderen Problemen, die auf ein Arzneimittel zurückzuführen sind, als auch die allgemeine Post-Market-Überwachung sind nicht nur gesetzlich vorgeschrieben, sondern auch eine wichtige Informationsquelle für die Pharmaindustrie. Einige Daten werden zwar durch dedizierte Systeme strukturiert erfasst, doch öffentliche Quellen wie soziale Medien, Foren- und Blogbeiträge oder auch interne Dokumente sind unstrukturiert. LLMs können aus diesen Quellen auf sehr effiziente Weise strukturierte Daten erstellen. Damit beschleunigen sie den allgemeinen Prozess und erhöhen die Qualität durch Daten, die ohne sie nur schwer oder gar nicht verwendbar wären.
Das bringt strukturierte Datenextraktion mit LLMs
In LLMs steckt ein erhebliches Potenzial für die Extraktion strukturierter Daten in der Pharma- und Life Science-Branche. Die Möglichkeit, mit ihrer Hilfe die Extraktion zu automatisieren und komplexe Erkenntnisse aus den Daten zu gewinnen, kann die Innovationskraft der Branche deutlich stärken und helfen, bessere Entscheidungen zu treffen.

Mit LLMs Dossiers erstellen
Eine der wichtigsten Aufgaben innerhalb der Pharmaindustrie ist die Erstellung ausführlichen Dossiers, die beispielsweise für die Genehmigung von klinischen Studien, klinische und vorklinische Protokolle, Forschungsprotokolle und Zielgruppenspezifische Berichte verwendet werden. Diese komplexen Dokumente werden aktuell von Expertenteams erstellt, die manuell riesige Datenmengen sammeln, auswerten und organisieren. Der Prozess kostet viel Zeit, ist ressourcenintensiv, schwer zu standardisieren und zudem oft fehleranfällig.
Standardisierung und Konsistenz erreichen
Das Erstellen von Dossiers ist aufgrund der schieren Datenmenge und der strengen Anforderungen verschiedener Aufsichtsbehörden und Zielgruppen aktuell meist nicht effizient. Zudem ist es schwierig oder sogar unmöglich, immer einheitliche Standards einzuhalten – besonders bei großen Organisationen mit vielen räumlich verteilten Abteilungen und entsprechend vielen Spezialist:innen. Hier können LLMs Abhilfe schaffen.
Wie können die Herausforderungen bei der Erstellung von Dossiers überwunden werden?
Die manuelle Erstellung von Dossiers steckt voller Herausforderungen. Sie kostet viel Zeit und ist ressourcenintensiv – das führt zu höheren Kosten und Verspätungen beim Einreichen von Unterlagen. Inkonsistenzen und Fehler durch den Faktor Mensch sind wahrscheinlich und können gegebenenfalls die Annahmequote für eingereichte Unterlagen negativ beeinflussen. Um die Richtigkeit und Vollständigkeit der Informationen sicherzustellen, ist die Qualitätssicherung von großer Bedeutung. Allerdings stellt die Qualitätssicherung eine besonders große Herausforderung dar, wenn Hunderte Menschen in verschiedenen, über die ganze Welt verteilten Teams Dokumente mit einheitlichem Erscheinungsbild und in einer standardisierten Sprache erstellen müssen.
Selbst mit der Unterstützung von umfangreichen Suchwerkzeugen und Dokumentenverwaltungssystemen ist es fast unmöglich, immer alle potenziell relevanten Datenquellen zu kennen und sie einzubeziehen – ganz besonders dann, wenn die Nachverfolgung von regelmäßigen Änderungen sehr vorteilhaft wäre. Es ist nicht möglich, immer sofort auf Änderungen zu reagieren, wenn die Arbeit von Menschen ausgeführt werden muss.
Welche Chancen eröffnet die Verwendung von LLMs zur Erstellung von Dossiers?
Generative KI und LLMs können diese Herausforderungen effektiv angehen, indem sie den Erstellungsprozess automatisieren. Die Modelle können riesige Datenmengen analysieren und korrekte, umfangreiche Dokumente nach spezifischen Vorgaben erstellen. Das spart Zeit und Ressourcen. Dadurch können Organisationen ihre Compliance- und Kommunikationsprozesse strategischer angehen.
Allerdings ist zu beachten, dass Expert:innen weiterhin eine wichtige Rolle in diesem Prozess spielen werden. Ihr Hauptaugenmerk wird sich allerdings von der Erstellung von Inhalten zur Überprüfung, Beurteilung und Finalisierung der Inhalte verlagern. So wird ihr Expertenwissen wesentlich effektiver genutzt. Zusätzlich zur höheren Effizienz wird so auch die Qualität verbessert, da die Expert:innen sich auf die wirklich wichtigen Aspekte konzentrieren können.
Welche Vorteile bietet die Erstellung von Dossiers mit LLMs?
- Effizienz: Die KI-Automatisierung mithilfe von LLMs kann die Erstellung von Dossiers deutlich beschleunigen und ressourcenschonender gestalten. Desweiteren ermöglichen LLMs die effektivere Kommunikation mit verschiedenen Interessengruppen, ohne dass zeitraubende manuelle Umformulierungen von Dokumenten notwendig werden. All diese Vorteile führen zu Kostenersparnissen und einer Verkürzung der Time-to-Market.
- Richtigkeit: Die Nutzung von LLMs kann menschliche Fehler minimieren. Außerdem sind mehr Quellen verwendbar, sodass in Verbindung mit der Expertise menschlicher Spezialisten die Qualität und Konsistenz von Dossiers erhöht wird.
- Erfolgreiche Anträge: LLMs können Dossiers analysieren, kritische Passagen identifizieren und die Erfolgschancen für Anträge vorhersagen. So können Unternehmen strategisch planen und potenzielle Probleme vor der Einreichung angehen.
- Kapazitäten: Anders als Menschen, deren Kapazitäten begrenzt sind, können LLMs skaliert werden und so große Datenmengen mit einer fast unendlichen Anzahl an Aufgaben verarbeiten. So können selbst für die Bereiche qualitativ hochwertige Dossiers erstellt werden, die bisher aus Ressourcenmangel vernachlässigt wurden. Es wird damit nicht nur möglich, mehr Dossiers zu erstellen, sondern auch deren Konsistenz über alle Organisationsbereiche hinweg sicherzustellen.
Herausforderungen bei der Verwendung von LLMs zur Erstellung von Dossiers
- Implementierung: LLMs müssen in die bestehenden Systeme integriert und mit relevanten Daten trainiert werden. Es ist äußerst wichtig sicherzustellen, dass das KI-System das vorhandene und zukünftige Datenvolumen sowie die Datenkomplexität verarbeiten kann und gleichzeitig die erforderliche Fachsprache für die jeweilige Anwendung beherrscht.
- Sicherheit: Die Verwendung von KI bietet vielversprechende Lösungen, doch auch die möglichen Fallstricke sollten nicht übersehen werden. Um Probleme zu vermeiden, sollten Unternehmen sicherstellen, dass ihr LLM die relevanten Datensicherheits- und Datenschutzanforderungen erfüllt, potenzielle ethische Komplikationen in Bezug auf die Verwendung von KI vermeidet und den Entscheidungsprozess der KI transparent macht.
- GenAI-Kompetenz: Die Identifizierung von kritischen Passagen und die Vorhersage der Erfolgschancen für Anträge ist ein potenziell sehr wertvolles strategisches Werkzeug. Die Unternehmen sollten allerdings ihre Mitarbeiter:innen fortbilden, sodass sie in der Lage sind, die Qualität der Resultate zu bewerten.
Weitere Use Cases zum Erstellen von Dossiers mit LLMs
Dossiers zu klinischen Studien:
LLMs können zur Erstellung von umfassenden Dossiers für klinische Studien verwendet werden. Sie können Daten aus vorangegangenen Versuchsphasen analysieren, die Struktur an spezifische regulatorische Vorgaben anpassen und mögliche Probleme identifizieren, die den Zulassungsprozess erschweren könnten.
Protokollierung:
LLMs können Protokolle für klinische und vorklinische Phasen generieren. Dabei können sie auch die Versuchsgestaltung und die Resultate analysieren und somit übersichtliche und präzise Protokolle erstellen, die auf verschiedene Zielgruppen zugeschnitten sind.
Risikobewertung:
Während der Erstellung von Dossiers kann das LLM kritische Stellen in den Eingabedaten ausfindig machen, herausstellen und die Erfolgschancen für den jeweiligen Zweck (beispielsweise die Einreichung bei Behörden) im Voraus abschätzen. Dadurch ist es der jeweiligen Organisation möglich, strategisch zu planen und mögliche Hindernisse proaktiv anzugehen.
Bedarfsgemäße Berichte:
Die Erstellung umfassender Berichte wird weiterhin erschwert, wenn diese Berichte für verschiedene Zielgruppen erstellt werden müssen. LLMs können aus den Originaldaten zielgruppenspezifische, fokussierte Berichte erstellen – quasi in Echtzeit.

Das bringt das Erstellen von Dossiers mit LLMs
Die Nutzung von LLMs zur automatisierten Erstellung von Dossiers kann die Pharma- und Life Science-Branche potenziell revolutionieren, indem sie die Effizienz und Genauigkeit steigert und die strategische Entscheidungsfindung deutlich verbessert. Diese Technologie ist nicht nur eine mögliche Option für die Zukunft – sie ist schon jetzt eine praktische Lösung, die nur darauf wartet, dass Unternehmen das vorhandene Potenzial ausschöpfen.

5 Guidelines für die Implementierung von LLMs
Wie oben dargestellt, können Unternehmen in der Pharma- und Life Science-Branche durch LLMs viele Vorteile erlangen, müssen allerdings auch einigen Herausforderungen bei der Implementierung gegenübertreten. Die folgenden fünf Grundprinzipien können helfen, diese Hindernisse zu überwinden.
1. Use Case definieren
Während LLMs in ihrer aktuellen Form offenbar eine bahnbrechende Innovation sind, die in allen Branchen und Lebensbereichen zu deutlichen Veränderungen führen werden, ist es dringend notwendig, den aktuellen Hype um das Thema von seinem tatsächlichen Potenzial zu trennen. Daher ist für jeden einzelnen Use Case abzuschätzen, ob er tatsächlich von den spezifischen Fähigkeiten von LLMs profitieren würde. LLMs sind zwar eine sehr leistungsstarke Technologie, aber keine Allzwecklösung. Für manche (oben beschriebene) Use Cases sind sie ganz besonders wertvoll. Für andere Use Cases sind gängige und ausgiebig erprobte Machine Learning-Technologien wie Klassifizierung oder Clustering eventuell bessere Optionen. Das gilt beispielsweise für die Deduplizierung von Daten oder für Optimierungsprozesse bei Testdurchläufen. Außerdem ist es wichtig, die Kosten und Vorteile für jeden einzelnen Fall abzuwägen.
2. Das geeignete Large Language Model auswählen
Bei der Auswahl des richtigen Large Language Models für Ihre Organisation sind diverse Faktoren zu beachten, und die Wahl ist nicht immer einfach. Zunächst ist zu entscheiden, wie das Modell gehostet werden soll. In der Regel stehen hier On-premises- oder cloudbasierte Modelle zur Wahl. On-premises-Lösungen bieten mehr Kontrolle und Sicherheit, was sie zu einer guten Wahl für Organisationen mit strikten Datenschutzanforderungen macht. Mit diesen Lösungen können die Daten sicher innerhalb der Organisation selbst verbleiben. Andererseits bieten cloudbasierte Modelle mehr Flexibilität und Skalierbarkeit zu häufig niedrigeren Kosten. Sie sind dadurch eine besonders attraktive Option für Organisationen, die eine kostengünstige und leicht skalierbare Lösung suchen. Wie bei allen cloudbasierten Services ist es abhängig vom Use Case von Bedeutung, wo und wie der Cloud-Service gehostet wird.
LLM on-premises
Generative KI als As-a-Service-Lösung einführen, ein LLM selbst hosten oder in der Cloud? Im GenAI-Tech-Talk geben unsere Experten Antworten auf die 10 häufigsten Fragen von CDOs und CIOs zum Hosting von LLM-Lösungen.


Desweiteren sind eventuell schon Large Language Modelle vorhanden, die spezifisch für den vorliegenden Use Case trainiert und angepasst wurden und die sich daher besser eignen als die mit sehr allgemeinen Daten trainierten Modelle, die aktuell am häufigsten verwendet werden. In diesem Kontext sollte auch erwähnt werden, dass in vielen Fällen mehrere Modelle kombiniert werden können, um einen bestimmten Use Case abzudecken. Beispielsweise kann das Echtzeit-Scoring von Resultaten, die von einem sehr großen Modell geliefert werden, von einem separaten, kleineren Modell übernommen werden, um Kosten zu sparen.
3. Die Datenlandschaft vorbereiten
LLMs führen kontextspezifische Aktionen auf der Detailebene aus. Dazu müssen Daten, Semantik, Wissen und Methoden auf die entsprechende Domäne angepasst sein. Um das zu erreichen, müssen Beschaffung, Vermehrung, Veredelung, Schutz und Einsatz der Daten strategisch geplant und diszipliniert verfolgt werden. Eine effektive Daten-Governance und MLOps sind fundamentale Bestandteile, um ein angemessenes Datenmanagement sicherzustellen. Unter anderem müssen Datenqualität, Datenschutz und -sicherheit sichergestellt und den regulatorischen Standards entsprechende Datenmanagement-Prozesse implementiert werden. Auch ethische Bedenken wie beispielsweise in den Trainingsdaten enthaltene Verzerrungseffekte und Tendenzen müssen ebenfalls angesprochen werden. Eigene Entwicklungen wie zum Beispiel Ontologien können den Daten Struktur und Kontext verleihen und so helfen, die Daten zu organisieren und sie leichter abrufbar und nutzbar zu machen.
Außerdem sollte unbedingt bedacht werden, dass Training und Data Literacy entscheidend sind. Die Mitarbeiter:innen entlang der gesamten Wertschöpfungskette sollten in der Verwendung von GenAI/des LLM für ihre jeweiligen Arbeitsaufgaben geschult werden. Dadurch wird sichergestellt, dass sie die notwendigen Fähigkeiten haben, um diese Technologie effektiv zu verwenden und zur erfolgreichen Implementierung und Nutzung des LLMs innerhalb der Organisation beitragen zu können.
4. Compliance- und Sicherheitsmaßnahmen einrichten
Die Compliance mit rechtlichen Bestimmungen zu Datenschutz und IT-Sicherheit ist für die stark regulierte Pharma- und Life Science-Branche von großer Bedeutung. Zum Training von LLMs sind große Datenmengen erforderlich. Ein Teil dieser Daten kann sensible Daten enthalten. Die Modelle müssen die geltenden Datenschutzgesetze und -bestimmungen sowie interne Compliance-Regeln einhalten. Angesichts der Herausforderungen in Bezug auf Compliance oder Regulatorik kann auch hier die Nutzung einer On-premises-Lösung sinnvoll sein.
Zusätzlich können Datenschutzmaßnahmen wie das Identity and Access Management (IAM) oder Zero Trust sicherstellen, dass nur autorisierte Personen Zugang zu bestimmten Daten haben. Das ist dringend erforderlich, um die Integrität und Vertraulichkeit der Daten zu wahren.


Was heißt Zero Trust?
Was zeichnet eine gute Zero Trust-Architektur aus? Auf welche relevanten Säulen sollten Sie sich bei der Umsetzung in Ihrem Unternehmen fokussieren? Dr. Jan Ciupka hat für Sie die wichtigsten Informationen rund um dieses Cyber-Security-Konzept zusammengestellt.
5. Die GenAI-Readiness der Organisation sicherstellen
Zusätzlich zu den technischen Anforderungen ist es zudem wichtig, dass auch die Mentalität und die Kultur einer Organisation für die Verwendung von LLMs und GenAI-Lösungen bereit sind. Das bedeutet einerseits, dass die Mitarbeiter:innen im Umgang mit LLMs geschult werden müssen, um die Resultate validieren und ggf. korrigieren zu können. Andererseits ist es für nachhaltige Innovationen wichtig, dass die Mitarbeiter:innen selbst LLM-Use Cases identifizieren und Verbesserungen entwickeln können. Dafür müssen sie die Möglichkeiten und Grenzen der Technologie verstehen und sich bewusst sein, welche Chancen und Risiken mit LLMs einhergehen. LLM- bzw. GenAI-Readiness und Datenkompetenz gehen dabei Hand in Hand. Schließlich hängt die Qualität der vom LLM generierten Inhalte von der Qualität der Daten ab – und die Datenqualität hängt ihrerseits davon ab, dass Daten korrekt eingepflegt und verwaltet werden.
Haben Sie Fragen?
Wenn Sie sich für Generative KI und Large Language Models interessieren und sich zu der Thematik weiter austauschen möchten, wenden Sie sich gerne an Dr. Benedikt Reiz und seine Kolleg:innen. Wir freuen wir uns auf Ihre Nachricht!